Uso attuale dell'AI
Debug, spiegazione di codice, documentazione, snippet, supporto su codice COBOL/web e ricerca tecnica.
Dispensa completa del corso
Sessioni 1-4
Riepilogo operativo
Debug, spiegazione di codice, documentazione, snippet, supporto su codice COBOL/web e ricerca tecnica.
Differenza tra chat tradizionale e strumenti che lavorano su progetto, file system, terminale e browser.
Ambienti cliente isolati, dati sensibili, copia-incolla limitato e uso degli screenshot come input.
Creazione di dati mock, web app locale, caricamento screenshot, OCR programmatico, note ed export CSV.
Chat, progetto, agente
La differenza pratica è l'accesso al progetto e agli strumenti necessari per verificare il lavoro.

Utile per spiegazioni, snippet, revisione di testi e ragionamento su contenuto incollato.
Utile quando il risultato deve diventare file, app, script, test o modifica verificabile.
Prima dei tool
La sessione ha richiamato alcune verifiche minime prima di usare strumenti AI con materiale di lavoro.
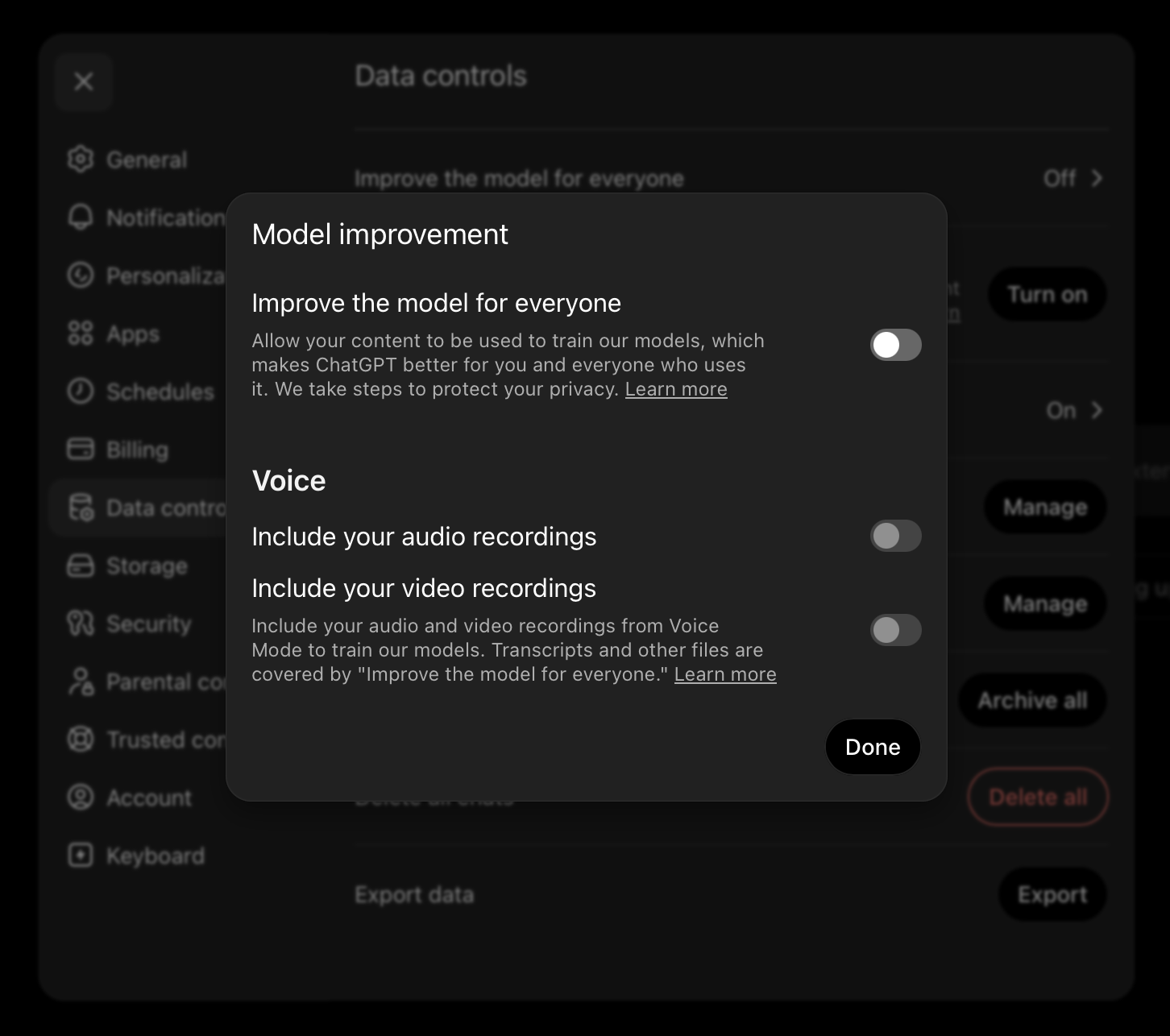
Controllare le impostazioni del servizio e disattivare il training sui dati quando l'opzione è disponibile.
Per sviluppo e demo usare dataset mock o esempi anonimizzati, non dati cliente.
Valutare accesso a file, browser, terminale e presenza di file sensibili come .env.
COBOL / mainframe
Nel lavoro su ambienti cliente non sempre è possibile copiare codice, errori o schermate in modo diretto.
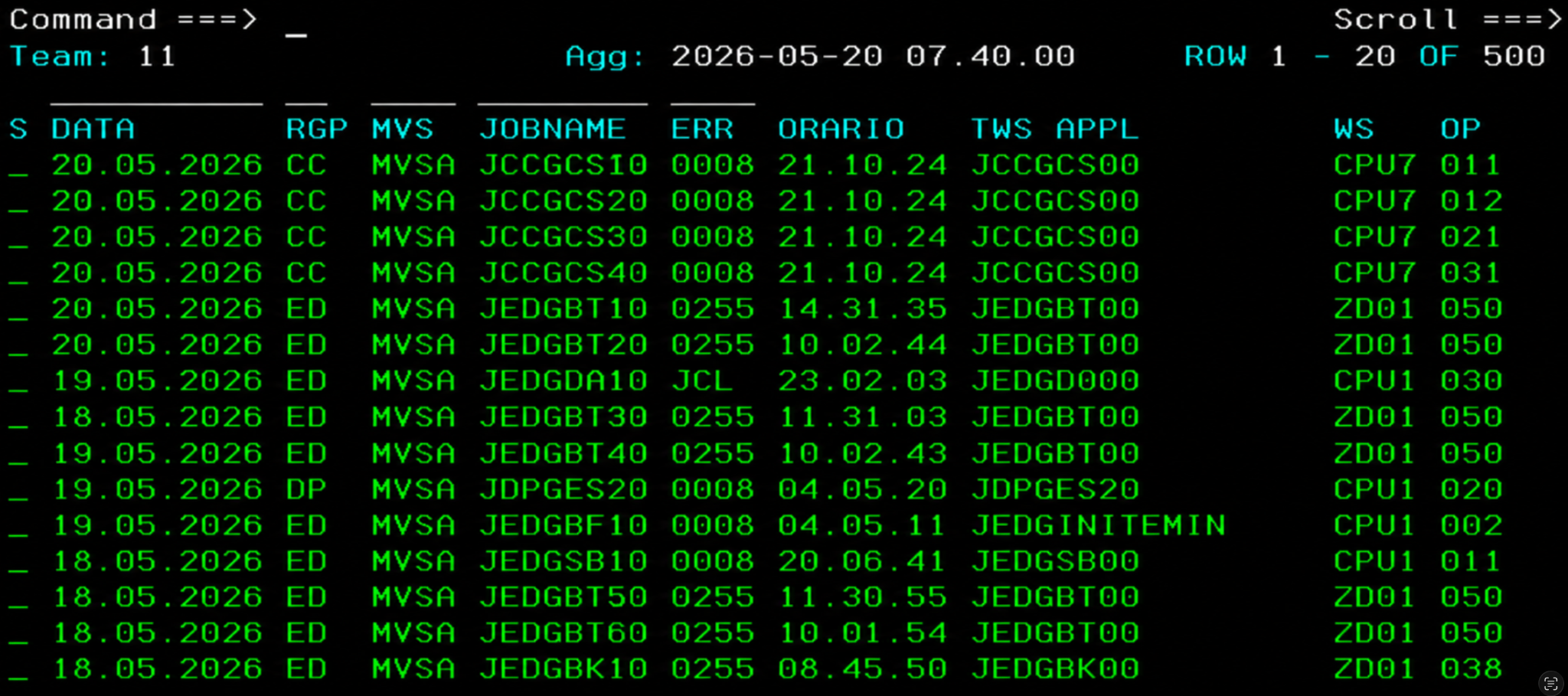
Il problema non è solo scrivere codice: spesso mancano input trasferibili verso l'AI o verso strumenti propri.
I codici degli errori e i dati dei job possono restare bloccati dentro schermate mainframe o sessioni remote.
Gli screenshot diventano un passaggio realistico per estrarre dati tramite OCR o modelli vision.
Caso pratico
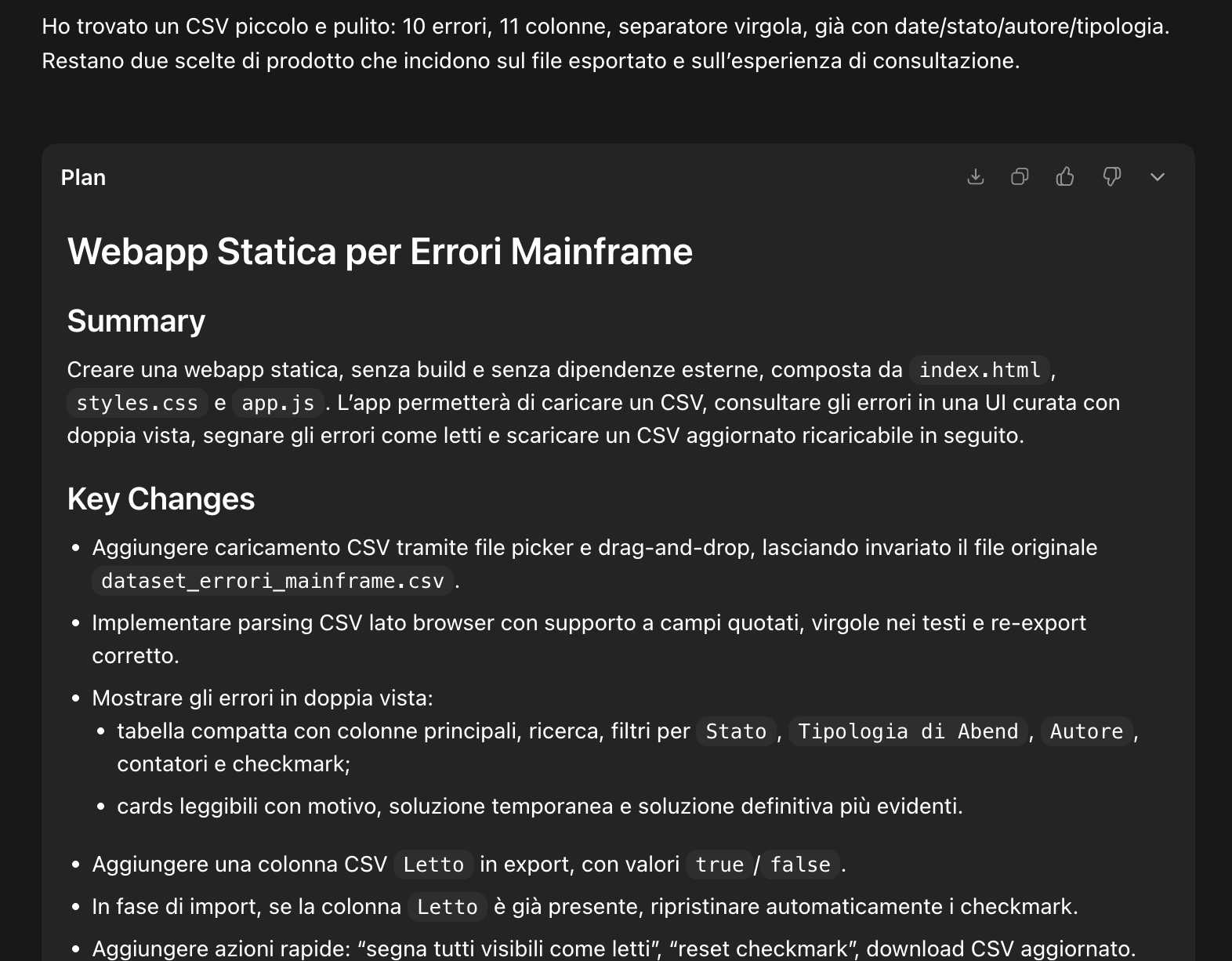
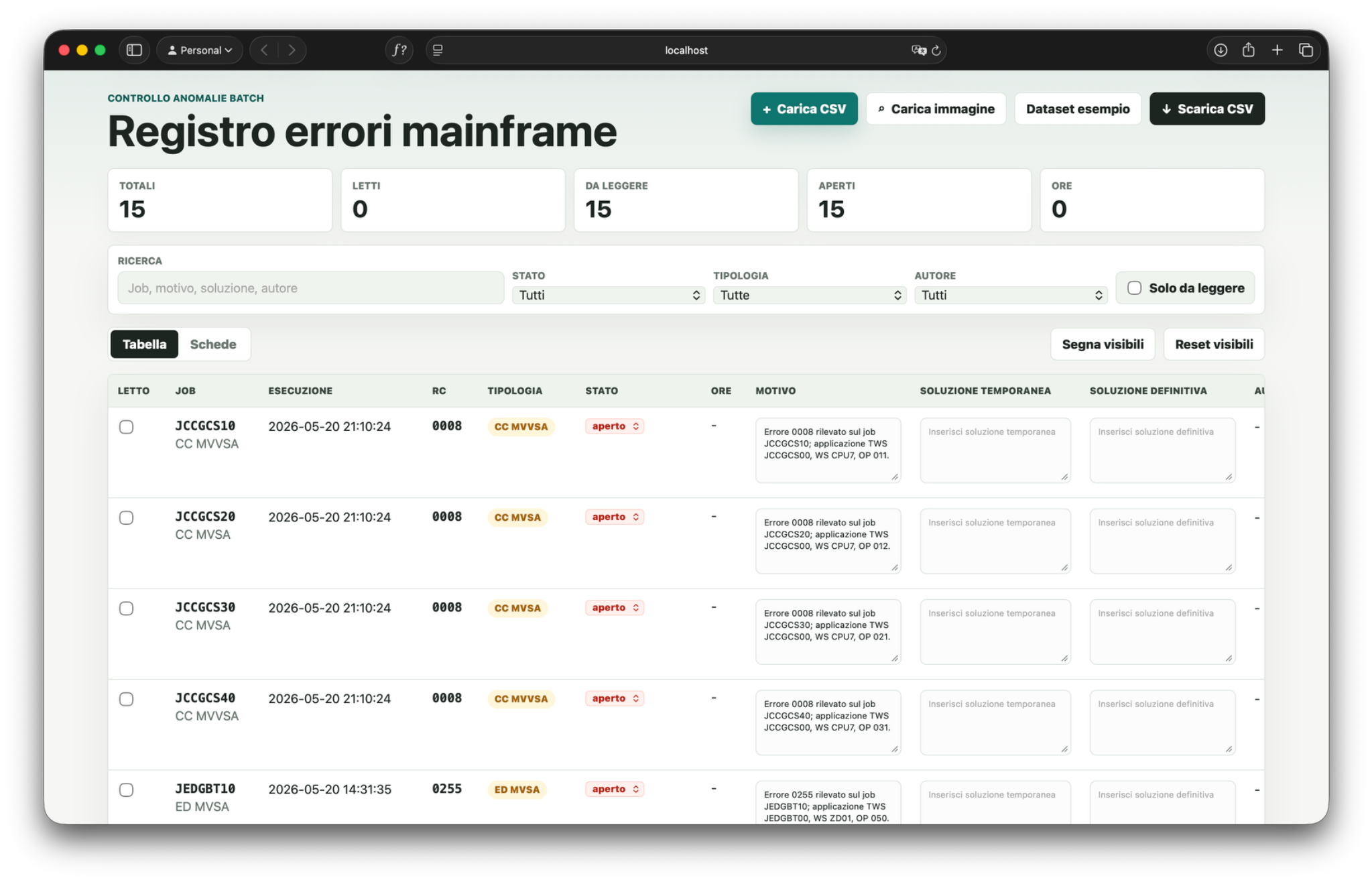
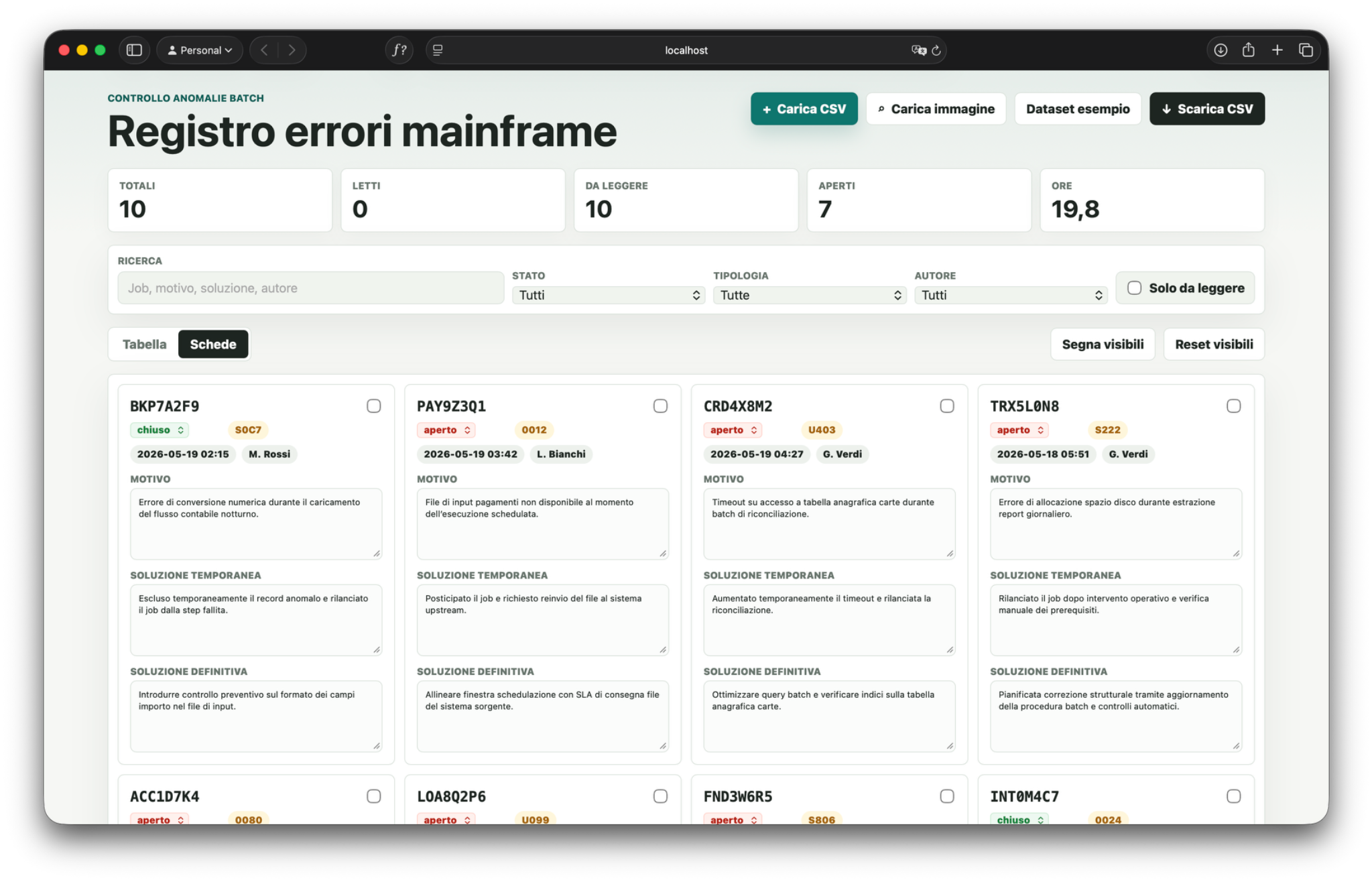
Obiettivo: ottenere una web app locale per consultare errori mainframe, aggiungere note e riesportare i dati.
Job notturni, errori, motivi, soluzioni e stato di lavorazione.
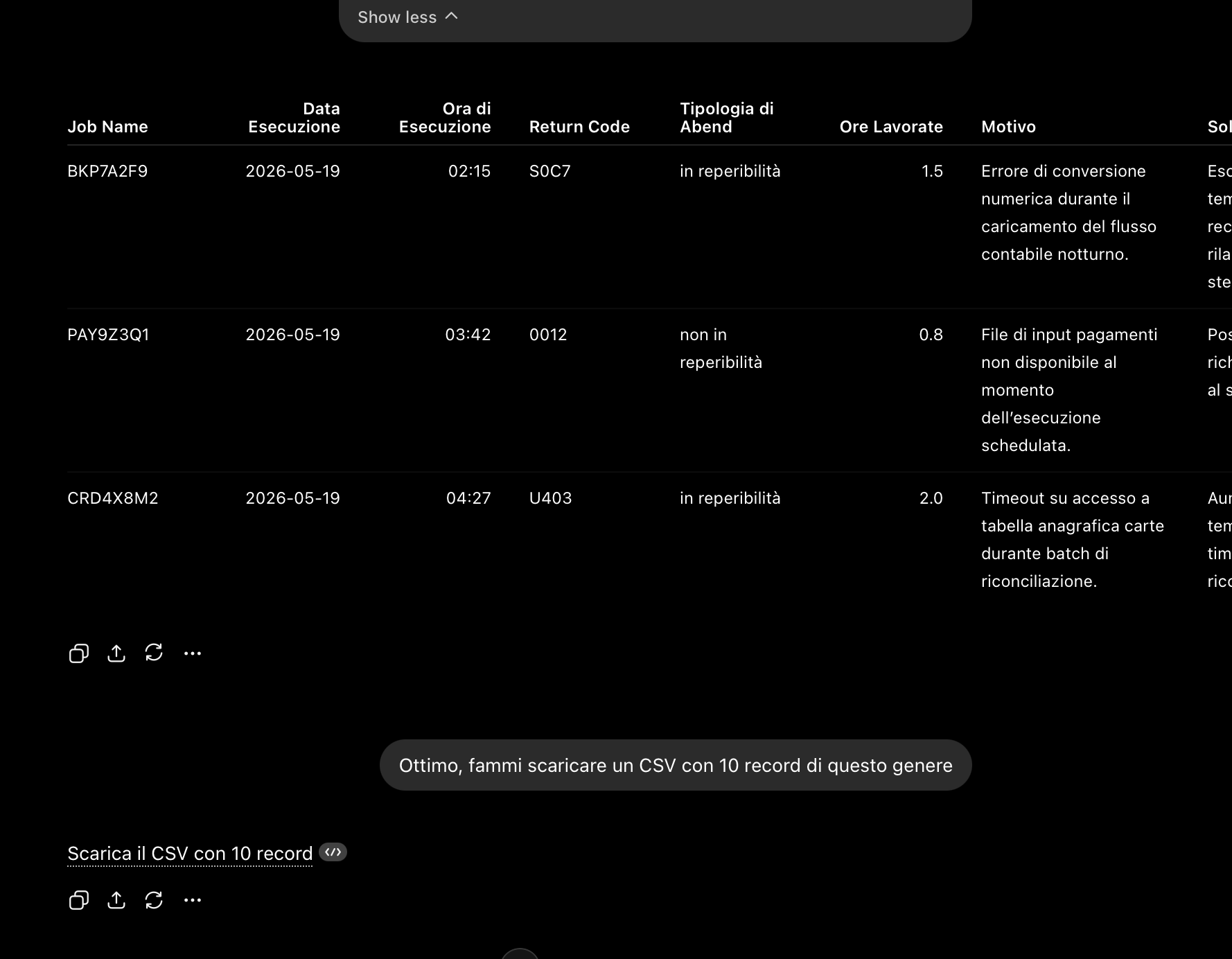
CSV realistico generato senza dati sensibili.
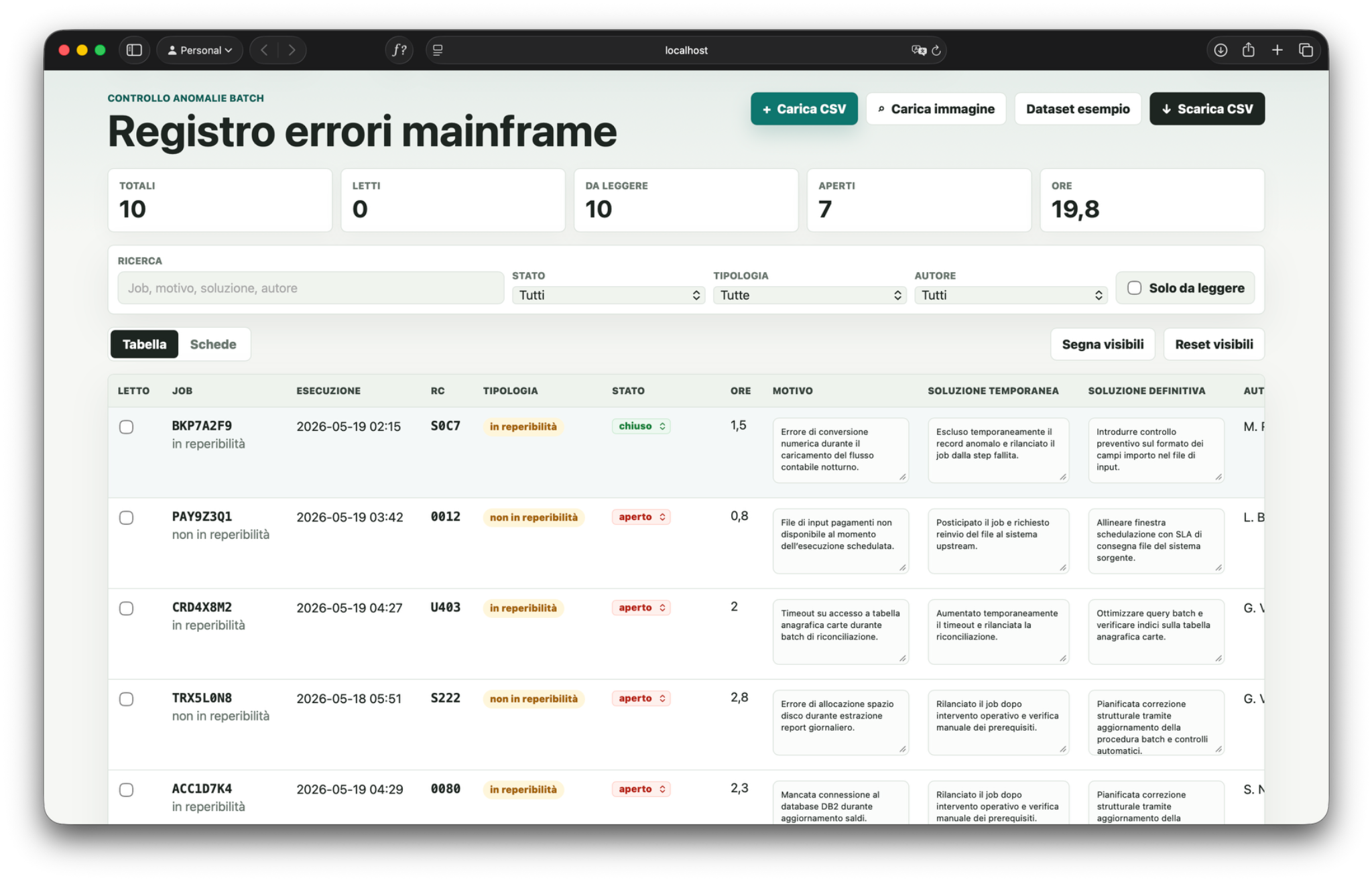
Caricamento CSV, filtri, modifica campi, note ed export.
Immagine mock usata come input di test.
Estrazione dei record e parsing dei campi.
Dati visualizzati in UI pulita e scaricabili.
Sviluppo senza dati sensibili

Codex
La demo ha usato una cartella progetto con i file di lavoro e ha definito prima le funzioni della web app.
Mainframe → app locale
Chi lavora sul mainframe non sempre può copiare facilmente i codici degli errori o passarli all'AI e ai propri strumenti di tracking.
Schermata mainframe o screenshot mock con lista di job, return code, orari e altri campi.
Caricamento dello screenshot nella web app, OCR programmatico, parsing dei record e correzioni mirate sui caratteri problematici.
Interfaccia leggibile per consultare gli errori, aggiungere note operative e scaricare un CSV aggiornato.
Risultato della demo
Caricamento dati, ricerca, filtri, stato e download del file aggiornato.
Caricamento immagine, OCR locale/programmatico e import dei record estratti.
Campi operativi modificabili, indicatore di modifica e copia negli appunti.
Sintesi operativa
Un tool locale con input e output chiari è un buon primo caso d'uso per strumenti agentici.
Prima si replica la forma dei dati; solo dopo si valuta come gestire dati reali, permessi e sicurezza.
Codex può avviare server, usare browser, verificare funzioni e correggere problemi emersi nel test.
Screenshot e OCR sono una strada praticabile quando l'ambiente mainframe non permette esportazioni dirette.
Database, dashboard, deploy controllato e diagrammi di esecuzione COBOL sono estensioni naturali del caso visto.
Workflow su progetti reali
Il lavoro è partito dal prototipo della web app errori e ha raccolto casi d'uso emersi dagli schermi condivisi dai partecipanti.
Excel strutturati, Excel complessi, TXT esportati dal mainframe e dati da anonimizzare.
Codex e Antigravity su cartella progetto, con permessi, test, comandi e iterazioni.
Visualizzatori, documentazione Docusaurus, scraper PDF, snippet JCL/ZCL, Git e test.
Excel / TXT / mainframe
Abbiamo distinto due scenari molto diversi: file tabellari usabili come database e fogli Excel costruiti per uso umano.
Colonne coerenti, intestazioni chiare e un tipo di dato per campo. Bastano spesso poche righe per capire schema, significato e manipolazioni possibili.
Formule, riferimenti tra celle, layout particolari, celle unite e dati distribuiti nel foglio. L'AI deve leggere più contesto e fare più inferenze.
Scelte operative
La differenza rispetto a una chat tradizionale è che l'agente può lavorare direttamente sui file e verificare il risultato.
Può ispezionare CSV, Excel, TXT, cartelle di snippet, immagini e file generati, invece di ragionare solo su contenuto incollato in chat.
Può creare parser, utility, visualizzatori HTML, script di conversione o controlli sui dati, rendendo riutilizzabile il lavoro.
Può eseguire comandi, verificare build, aprire il browser, leggere errori e iterare fino a un risultato funzionante.
Token, modelli, privacy
Abbiamo discusso quote, reasoning, scelta del modello e attenzione ai dati prima di caricare materiale aziendale reale.
Più adatti a pianificazione, architettura, debug, refactoring e file difficili; consumano più risorse.
Utili per modifiche semplici, piccoli fix UI, testi e task ripetitivi con contesto limitato.
Lanciare più agenti su più progetti consuma molto più velocemente rispetto a un uso sequenziale.
Anonimizzare codici e riferimenti, usare ambienti enterprise e mantenere intatta la struttura utile al test.
File TXT mainframe
Un caso discusso riguardava un file esportato dal mainframe con relazioni tra sistemi, job, applicazioni e dipendenze operative.
Prima di visualizzare, l'agente deve riconoscere formato, righe, codici e tipo di relazione tra gli elementi.
Il file può essere reso sicuro per i test modificando codici e riferimenti senza rompere formato e collegamenti.
Mermaid o Markdown sono utili per diagrammi semplici; un visualizzatore HTML serve quando le relazioni sono molte.
PDF / scraping / workflow
Il caso discusso riguardava una pagina ufficiale dove vengono pubblicati periodicamente PDF con dati finanziari.
Verificare se esiste un nuovo documento, scaricare il PDF corretto e associare il file al trimestre giusto.
Combinare testo estratto dal PDF, screenshot della tabella e un CSV passato già corretto come esempio.
Segnalare nuove categorie, classi di importo, colonne inattese o formati incompatibili con gli output precedenti.
Registrare ultima esecuzione, stato, errori, anomalie, output e log invece di lasciare script isolati.
Ho trovato un CSV piccolo e pulito: 10 errori, 11 colonne, separatore virgola, già con date/stato/autore/tipologia. Restano scelte di prodotto che incidono sul file esportato e sull'esperienza di consultazione.
Vista tabella e schede, filtri, campi modificabili, stato di lettura, download del CSV aggiornato.
Fatto: ho creato il nuovo progetto Cloudflare Pages registro-errori-mainframe e caricato l'interfaccia.
URL pubblico verificato:
https://registro-errori-mainframe.pages.dev/Per ridistribuire aggiornamenti dalla cartella progetto:
bashcd "/Users/ig/dev/Tualba/Primo test codex 01"
npx wrangler pages deploy . --project-name registro-errori-mainframe --branch main
Fatto. Ho creato la documentazione Docusaurus in docs-site, con tema light di default, switch dark disabilitato e accent color verde #bcda56 campionato dall'immagine.
La documentazione locale è già avviata qui:
http://127.0.0.1:3000/Comandi utili:
bashcd "/Users/ig/dev/Tualba/Primo test codex 01/docs-site"
npm run start
Build produzione:
bashcd "/Users/ig/dev/Tualba/Primo test codex 01/docs-site"
npm run build
npm run serve -- --host 127.0.0.1 --port 3000
Verifiche fatte: npm install, npm run build ok, check browser ok su homepage, tema light, background bianco, accent #bcda56, nessun errore console.
Fatto. Ho aggiunto screenshot reali in docs-site/static/img/screenshots/ e li ho inseriti nelle sezioni Docusaurus più utili: panoramica, guida utente, OCR, stati/modifiche e sviluppo locale.
Build verificata con:
bashcd "/Users/ig/dev/Tualba/Primo test codex 01/docs-site"
npm run build
Risultato: build OK, immagini renderizzate correttamente, nessun errore console nel browser.
Fatto. Ho creato il nuovo progetto Cloudflare Pages:
documentazione-tualba-error-tracker
URL pubblico verificato:
https://documentazione-tualba-error-tracker.pages.dev/Ho anche aggiornato docs-site/docusaurus.config.js e la pagina docs/deploy.md per puntare al nuovo dominio della documentazione.
Per pubblicare futuri aggiornamenti:
bashcd "/Users/ig/dev/Tualba/Primo test codex 01/docs-site"
npm run build
npx wrangler pages deploy build --project-name documentazione-tualba-error-tracker --branch main
Verifiche fatte: build Docusaurus ok, deploy ok, homepage pubblica HTTP 200, rotta /docs/intro raggiungibile.
Snippet e versioning
Sono stati discussi progetti piccoli ma utili: cartelle di snippet, istruzioni persistenti e commit ordinati.
Blocchi JCL/ZCL già ordinati e formattati, suddivisi per tipologia, usati come base per generare scheletri coerenti.
Regole importanti in README, file di istruzioni, esempi di output e convenzioni di naming; non solo nella chat.
L'AI può leggere le modifiche, separarle in commit sensati e proporre messaggi descrittivi coerenti.
Può aiutare a risolvere conflitti leggendo entrambe le versioni, ma il risultato va verificato con test o review.
COBOL legacy
La parte finale della sessione ha anticipato il lavoro su programmi COBOL storici e routine difficili da modificare.
AI per spiegare codice legacy, produrre documentazione tecnica e funzionale, manuali, guide SIT e pagine navigabili.
Definire input, output attesi, casi limite, quadrature e confronti prima/dopo per ridurre il rischio del refactoring.
Refactoring o migrazione verso Java, Python, C o altri linguaggi ha senso solo se il comportamento è verificabile.
Riepilogo operativo
Una routine, un file, un output atteso o una schermata sono più utili di una richiesta troppo generica.
Anonimizzare i dati sensibili senza distruggere formato, relazioni e casi limite necessari al test.
Script, test, CSV, documentazione o web app sono più controllabili di una spiegazione isolata.
Git, note, log e documentazione servono a capire cosa è cambiato e perché.
Questa parte del corso si è concentrata su un workflow più trasversale rispetto agli argomenti precedenti.
L’obiettivo era mostrare come usare strumenti agentici come Codex, Antigravity e Gemini non solo su codice COBOL/mainframe, ma anche per:
Abbiamo visto la differenza tra una semplice chat AI e un agente di coding.
Un coding agent può:
Questo permette di passare da “chiedere codice” a far costruire parti funzionanti di un’applicazione.
Abbiamo introdotto Codex CLI come modo per usare Codex da terminale.
Concetti principali:
La CLI rende Codex più adatto a workflow tecnici e ambienti remoti.
Caricamento transcript...
Abbiamo confrontato l’uso di Codex sul laptop con l’uso su server.
Lavorare su server può essere utile perché:
Per iniziare va bene il locale, ma per workflow avanzati il server è spesso più comodo.
Un punto operativo importante: Codex va lanciato dentro una cartella progetto dedicata.
Meglio evitare di avviarlo dalla home directory, perché lì potrebbero esserci file personali o dati non necessari.
Abbiamo anche visto che i permessi possono essere gestiti su diversi livelli:
Abbiamo ripreso il tema dell’uso efficiente dei modelli.
Indicazioni pratiche:
Il punto chiave: usare il modello giusto per il task giusto.
La demo principale è stata la creazione di un applicativo completo partendo da un prompt naturale.
L’app scelta era un gestionale per carte Pokémon, con:
L’obiettivo era mostrare quanto si può ottenere con un singolo prompt ben strutturato.
Il prompt è stato costruito specificando:
Più il prompt descrive il workflow reale, migliore sarà la base generata.
L’applicativo è stato richiesto con uno stack completo:
Questo mostra che l’AI può generare non solo schermate, ma anche architettura applicativa, servizi e configurazione.
Abbiamo introdotto ShadCN UI come libreria utile per dashboard e gestionali.
Vantaggi:
Abbiamo anche confrontato strumenti diversi: Gemini e Antigravity tendono spesso a produrre front-end più curati, mentre Codex migliora molto se viene guidato con stile, immagini o vincoli precisi.
Un workflow avanzato visto in sessione:
Questo aiuta a:
L’immagine diventa una sorta di brief visivo per l’agente.
Docker è stato usato per rendere l’app più portabile.
Serve a evitare il problema:
“Sul mio computer funziona, sul tuo no.”
Con Docker possiamo:
Abbiamo anche discusso l’importanza di persistenza dati, cartelle esterne e backup.
Abbiamo visto come un MVP locale può essere adattato per il deploy.
Cloudflare è stato citato come opzione pratica per piccoli tool perché offre:
Il principio: se sappiamo dove vogliamo deployare, conviene dirlo all’AI già in fase di progettazione.
Abbiamo discusso la possibilità di far lavorare più agenti sullo stesso progetto.
Esempio:
Questo può aumentare la produttività, ma richiede controllo: più agenti possono anche generare conflitti o modifiche inattese.
È stata introdotta la modalità Goal di Codex.
È utile quando il task è:
Esempi possibili:
Attenzione: se l’obiettivo non è ben definito, l’AI può lavorare a lungo nella direzione sbagliata.
Nella seconda parte siamo passati a un programma COBOL reale, lungo circa 6.400 righe.
L’obiettivo era capire come affrontare un refactoring importante.
Codex ha analizzato:
GO TO;Il primo valore dell’AI qui non è riscrivere subito, ma aiutare a capire dove intervenire.
La conclusione principale sul COBOL è stata: non partire da “riscrivi tutto”.
Prima serve costruire una base di verifica.
Workflow consigliato:
Senza test affidabili, un refactoring di codice legacy è troppo rischioso.
Abbiamo chiuso con alcune considerazioni sull’uso aziendale degli agenti AI.
Messaggi chiave:
Il tokenmaxxing NON è una best practice.
Questo è un progetto di refactoring della nostra codebase in Cobol. In questo progetto c’è un solo programma, piccola parte di un refactoring molto più grande, su cui dovremmo fare una prova di refactoring. Vorremmo inoltre testarlo per accertarci che funziona come dovrebbe, motivo per cui ti abbiamo fornito anche i file in input.
Fai un’analisi per capire se hai tutto quanto ti serve per procedere, e se hai dei suggerimenti su come procedere dimmi pure.
Considera queste corrispondenze tra il codice nel file cobol e i nomi di file in input:
AF = OF91P AC = FI80IC34 BC = FI80IC39 CC = FI80IC86 TT = OF63E TX = nessun file SYSIN = FI80OF92 FPARIST0 = FPARIST DEROGHE = DEROIC86 PRFLOOR = FLORIC86
Inizio mappando struttura del progetto, sorgente COBOL e dataset disponibili; poi verifico se le assegnazioni file nel programma sono coerenti con le corrispondenze indicate.
Ho trovato un solo sorgente principale, 5 copybook e tutti i dataset indicati; la directory non è un repository Git.
Il programma apre tre alias per TT e due alias per AF, quindi la parametrizzazione lunghezza record è una parte importante del test.
I dati non sono EBCDIC puro: vedo ASCII per i campi alfanumerici e byte binari/packed decimal nei campi COMP-3, coerente con dump di record mainframe.
Per AC, BC e AF torna un pattern chiaro: lunghezza logica COBOL più CRLF, con un byte finale 0x1A. CC/FI80IC86 richiede verifica più attenta.
Manca cobc nell’ambiente, quindi non posso fare una compilazione locale immediata. Per una prova end-to-end serviranno anche le routine chiamate dinamicamente o stub compatibili.
Per fare analisi e iniziare un refactoring controllato del programma principale c’è abbastanza: codice da analizzare/RRZ824.COB e copybook sono presenti. Per eseguire un test end-to-end locale, invece, mancano alcuni pezzi.
ACCEPT IF92. Il file FI80OF92 contiene un record da 25 byte valido.C’è anche un possibile bug già visibile: AF00-IDLIN2 viene mosso su WB55-IDLDC2 e WD91-IDLDC2, poi subito sovrascritto da AF00-IDLDC2. Sembra un copia/incolla, ma lo toccherei solo dopo golden master.
Questa che stiamo affrontando adesso è una demo dove sto mostrando ad un team che lavora in Cobol come possono utilizzare Codex per fare un refactoring di questo genere. Vorrei quindi che tagliassimo qualche angolo e procedessimo con la demo giusto per dimostrare il processo.
Pensa a cosa puoi fare per dimostrare le tue capacità di riuscita. Magari prova anche a mostrare un po’ di refactoring smart anche senza fare dei test, giusto per dimostrare che ne sei in grado.
Per la demo scelgo un taglio pragmatico: un refactoring reale ma circoscritto, senza provare a modernizzare tutto il monolite.
Ho individuato un punto adatto: il blocco F90TT contiene due copie quasi identiche della scrittura TT, e l’inizializzazione dei parametri si presta a EVALUATE TRUE.
Procedo con due modifiche dimostrative: trasformo la cascata di IF in EVALUATE TRUE e centralizzo la scrittura TT in un paragrafo F90WR.
Normalizzo i terminatori perché la patch aveva introdotto alcune righe LF in un file quasi tutto CRLF.
I controlli statici confermano l’effetto: le tre WRITE TX* ora esistono in un solo punto, richiamato da due percorsi.
RRZ824.COB:1733 la cascata di IF sui parametri TT/AF diventa una tabella decisionale leggibile con EVALUATE TRUE.RRZ824.COB:5625 la scrittura TT viene centralizzata: i due rami chiamano PERFORM F90WR THRU F90WR-FN.cobc non è disponibile e mancano le routine dinamiche.Installo GnuCOBOL se il sistema lo consente, poi provo almeno una compilazione statica del programma.
sudo apt-get richiede autenticazione interattiva. Provo una strada senza privilegi.
Docker è disponibile senza sudo. Uso quindi un’immagine locale con GnuCOBOL: è la soluzione più rapida per la demo e non richiede privilegi sull’host.
cobc funziona nel container: GnuCOBOL 3.2.0. Rendo l’installazione ripetibile con un Dockerfile.
La compilazione di sintassi passa: solo warning di dialetto/copybook senza newline, nessun errore.
Preparo uno smoke test eseguibile: driver COBOL + stub minimi per le routine dinamiche.
La build completa riesce: abbiamo RRZ824.so, gli stub dinamici e il driver.
Lo smoke con SYSIN vuoto funziona e restituisce RETURN-CODE=12 nel punto atteso.
Con SYSIN reale e input normalizzati il programma legge IF92, costruisce la tabella parametri fino a 39 elementi e poi si ferma in F9999 perché gli stub non implementano la logica business esterna.
Ho installato GnuCOBOL in modo ripetibile via Docker, perché sudo apt-get sull’host richiedeva autenticazione interattiva.
bashdocker build -t analisi-cobol-gnucobol:local tools/gnucobol
docker run --rm -v "$PWD:/work" analisi-cobol-gnucobol:local cobc --version
tools/gnucobol/Dockerfiletools/gnucobol/README.mdtools/gnucobol/prepare_inputs.pydemo/smoke/DRVRRZ824.COBRRZ824.COB passa la compilazione di sintassi con GnuCOBOL.build/gnucobol-data/output/full-smoke.log.Controllo la configurazione Docker locale, perché l’immagine non viene salvata come file nel progetto: Docker la mette nel suo storage interno. Verifico anche se restano container creati da quella immagine.
L’immagine Docker è salvata nello storage interno di Docker:
/var/lib/docker
Tag immagine usato:
analisi-cobol-gnucobol:local
sha256:7a408a2a912101fe1fa4c820179efd3ef35a9b5b082d97133e717e2dbe00cefd2026-06-17T11:02:54+02:00docker images: 465MBIl container non è rimasto salvato: è stato sempre lanciato con --rm, quindi Docker lo ha eliminato automaticamente a fine esecuzione. Il Dockerfile sorgente resta nel progetto: tools/gnucobol/Dockerfile.
Trainer
Senior AI Engineer & Trainer

